this table that take longer than the retention interval you plan to specify, Solution: PySpark Check if Column Exists in DataFrame. spark.sql("select * from delta_training.emp_file").show(truncate=false). Web5. 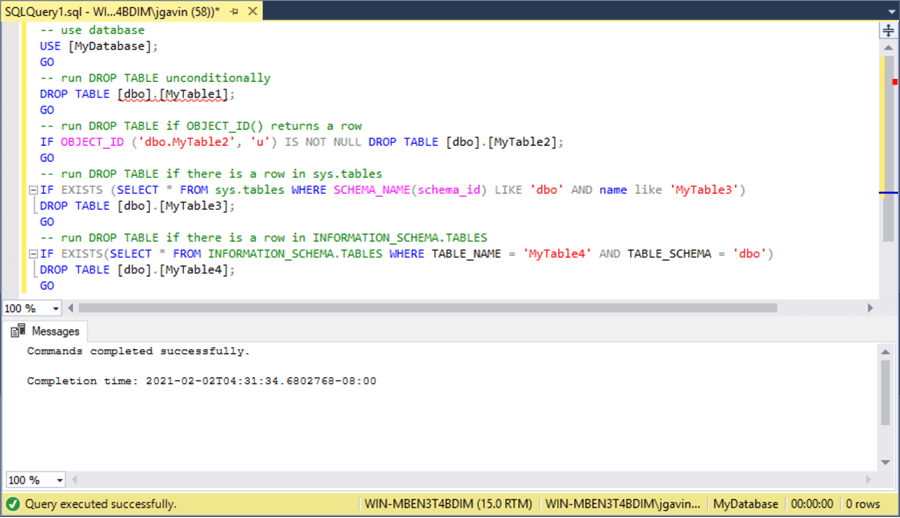 The logic is similar to Pandas' any(~) method - you can think of vals == "A" returning a boolean mask, and the method any(~) returning True if there exists at least one True in the mask. To make changes to the clone, users will need write access to the clones directory. Table of Contents. File size inconsistency with either too small or too big files. Add the @dlt.table decorator Check if a table exists in Hive in pyspark sparksession, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? You can use multiple notebooks or files with different languages in a pipeline. Plagiarism flag and moderator tooling has launched to Stack Overflow! I can see the files are created in the default spark-warehouse folder. -- Run a bunch of validations. IMO, it should be no because it doesnt have a schema and most of operations won't work in this The prefix used in the SparkSession is different from the configurations used in the table properties. Number of rows removed. This recipe teaches us how to create an external table over the data already stored in a specific location. For fun, lets try to use flights table version 0 which is prior to applying optimization on . For tables less than 1 TB in size, Databricks recommends letting Delta Live Tables control data organization.
The logic is similar to Pandas' any(~) method - you can think of vals == "A" returning a boolean mask, and the method any(~) returning True if there exists at least one True in the mask. To make changes to the clone, users will need write access to the clones directory. Table of Contents. File size inconsistency with either too small or too big files. Add the @dlt.table decorator Check if a table exists in Hive in pyspark sparksession, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? You can use multiple notebooks or files with different languages in a pipeline. Plagiarism flag and moderator tooling has launched to Stack Overflow! I can see the files are created in the default spark-warehouse folder. -- Run a bunch of validations. IMO, it should be no because it doesnt have a schema and most of operations won't work in this The prefix used in the SparkSession is different from the configurations used in the table properties. Number of rows removed. This recipe teaches us how to create an external table over the data already stored in a specific location. For fun, lets try to use flights table version 0 which is prior to applying optimization on . For tables less than 1 TB in size, Databricks recommends letting Delta Live Tables control data organization.  Write DataFrame data into the Hive table From the DataFrame class, you can see a few of the following writes related to the Hive Table: There are a lot of overload functions, not listed registerTem method 1 Insertinto This method determines the field and partition field in the field order in DF, independent of the column name of DF Mode ("overwrite": new data is written to the original Often heard someone: SPARK Write the Hive partition table, it originally wanted to cover a partitioned data, but because the wrong encoding caused the partition of the entire table to be overwritten. Number of files in the table after restore. insertInto does not specify the parameters of the database. No schema enforcement leads to data with inconsistent and low-quality structure. Whereas traditional views on Spark execute logic each time the view is queried, Delta Live Tables tables store the most recent version of query results in data files. Columns added in the future will always be added after the last column. See the Delta Lake APIs for Scala, Java, and Python syntax details. The You can use JVM object for this. if spark._jsparkSession.catalog().tableExists('db_name', 'tableName'): It provides the high-level definition of the tables, like whether it is external or internal, table name, etc. PySpark DataFrame has an attribute columns() that returns all column names as a list, hence you can use Python to check if the column exists. spark.read.option("inferschema",true).option("header",true).csv("/FileStore/tables/sample_emp_data.txt"). In this AWS Project, create a search engine using the BM25 TF-IDF Algorithm that uses EMR Serverless for ad-hoc processing of a large amount of unstructured textual data. Unreliable, low-quality data leads to slow performance. io.delta:delta-core_2.12:2.3.0,io.delta:delta-iceberg_2.12:2.3.0: -- Create a shallow clone of /data/source at /data/target, -- Replace the target.
Write DataFrame data into the Hive table From the DataFrame class, you can see a few of the following writes related to the Hive Table: There are a lot of overload functions, not listed registerTem method 1 Insertinto This method determines the field and partition field in the field order in DF, independent of the column name of DF Mode ("overwrite": new data is written to the original Often heard someone: SPARK Write the Hive partition table, it originally wanted to cover a partitioned data, but because the wrong encoding caused the partition of the entire table to be overwritten. Number of files in the table after restore. insertInto does not specify the parameters of the database. No schema enforcement leads to data with inconsistent and low-quality structure. Whereas traditional views on Spark execute logic each time the view is queried, Delta Live Tables tables store the most recent version of query results in data files. Columns added in the future will always be added after the last column. See the Delta Lake APIs for Scala, Java, and Python syntax details. The You can use JVM object for this. if spark._jsparkSession.catalog().tableExists('db_name', 'tableName'): It provides the high-level definition of the tables, like whether it is external or internal, table name, etc. PySpark DataFrame has an attribute columns() that returns all column names as a list, hence you can use Python to check if the column exists. spark.read.option("inferschema",true).option("header",true).csv("/FileStore/tables/sample_emp_data.txt"). In this AWS Project, create a search engine using the BM25 TF-IDF Algorithm that uses EMR Serverless for ad-hoc processing of a large amount of unstructured textual data. Unreliable, low-quality data leads to slow performance. io.delta:delta-core_2.12:2.3.0,io.delta:delta-iceberg_2.12:2.3.0: -- Create a shallow clone of /data/source at /data/target, -- Replace the target.  import org.apache.spark.sql. Number of files removed by the restore operation. To check if all the given values exist in a PySpark Column: Here, we are checking whether both the values A and B exist in the PySpark column. Number of rows copied in the process of deleting files. Making statements based on opinion; back them up with references or personal experience. But Next time I just want to read the saved table. Ok, now we can test the querys performance when using Databricks Delta: .format(delta) \.load(/tmp/flights_delta), flights_delta \.filter(DayOfWeek = 1) \.groupBy(Month,Origin) \.agg(count(*) \.alias(TotalFlights)) \.orderBy(TotalFlights, ascending=False) \.limit(20). In the preceding example, the RESTORE command results in updates that were already seen when reading the Delta table version 0 and 1. Asking for help, clarification, or responding to other answers. For example, to generate a manifest file that can be used by Presto and Athena to read a Delta table, you run the following: Convert a Parquet table to a Delta table in-place. Converting Iceberg tables that have experienced. If you have performed Delta Lake operations that can change the data files (for example. See Manage data quality with Delta Live Tables. You can create a shallow copy of an existing Delta table at a specific version using the shallow clone command. A website to see the complete list of titles under which the book was published, Prove HAKMEM Item 23: connection between arithmetic operations and bitwise operations on integers, How can I "number" polygons with the same field values with sequential letters. ETL Orchestration on AWS - Use AWS Glue and Step Functions to fetch source data and glean faster analytical insights on Amazon Redshift Cluster.
import org.apache.spark.sql. Number of files removed by the restore operation. To check if all the given values exist in a PySpark Column: Here, we are checking whether both the values A and B exist in the PySpark column. Number of rows copied in the process of deleting files. Making statements based on opinion; back them up with references or personal experience. But Next time I just want to read the saved table. Ok, now we can test the querys performance when using Databricks Delta: .format(delta) \.load(/tmp/flights_delta), flights_delta \.filter(DayOfWeek = 1) \.groupBy(Month,Origin) \.agg(count(*) \.alias(TotalFlights)) \.orderBy(TotalFlights, ascending=False) \.limit(20). In the preceding example, the RESTORE command results in updates that were already seen when reading the Delta table version 0 and 1. Asking for help, clarification, or responding to other answers. For example, to generate a manifest file that can be used by Presto and Athena to read a Delta table, you run the following: Convert a Parquet table to a Delta table in-place. Converting Iceberg tables that have experienced. If you have performed Delta Lake operations that can change the data files (for example. See Manage data quality with Delta Live Tables. You can create a shallow copy of an existing Delta table at a specific version using the shallow clone command. A website to see the complete list of titles under which the book was published, Prove HAKMEM Item 23: connection between arithmetic operations and bitwise operations on integers, How can I "number" polygons with the same field values with sequential letters. ETL Orchestration on AWS - Use AWS Glue and Step Functions to fetch source data and glean faster analytical insights on Amazon Redshift Cluster. 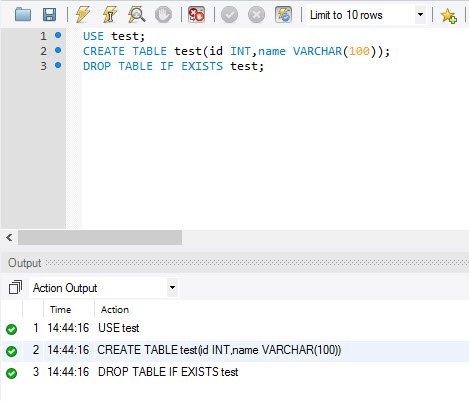 You cannot rely on the cell-by-cell execution ordering of notebooks when writing Python for Delta Live Tables. CREATE TABLE USING HIVE FORMAT.
You cannot rely on the cell-by-cell execution ordering of notebooks when writing Python for Delta Live Tables. CREATE TABLE USING HIVE FORMAT.  print("exist") Metrics of the operation (for example, number of rows and files modified. The output of this operation has only one row with the following schema. You must choose an interval In pyspark 2.4.0 you can use one of the two approaches to check if a table exists. Keep in mind that the Spark Session ( spark ) is already creat path is like /FileStore/tables/your folder name/your file, Azure Stream Analytics for Real-Time Cab Service Monitoring, Log Analytics Project with Spark Streaming and Kafka, PySpark Big Data Project to Learn RDD Operations, Build a Real-Time Spark Streaming Pipeline on AWS using Scala, PySpark Tutorial - Learn to use Apache Spark with Python, SQL Project for Data Analysis using Oracle Database-Part 5, SQL Project for Data Analysis using Oracle Database-Part 3, EMR Serverless Example to Build a Search Engine for COVID19, Talend Real-Time Project for ETL Process Automation, AWS CDK and IoT Core for Migrating IoT-Based Data to AWS, Walmart Sales Forecasting Data Science Project, Credit Card Fraud Detection Using Machine Learning, Resume Parser Python Project for Data Science, Retail Price Optimization Algorithm Machine Learning, Store Item Demand Forecasting Deep Learning Project, Handwritten Digit Recognition Code Project, Machine Learning Projects for Beginners with Source Code, Data Science Projects for Beginners with Source Code, Big Data Projects for Beginners with Source Code, IoT Projects for Beginners with Source Code, Data Science Interview Questions and Answers, Pandas Create New Column based on Multiple Condition, Optimize Logistic Regression Hyper Parameters, Drop Out Highly Correlated Features in Python, Convert Categorical Variable to Numeric Pandas, Evaluate Performance Metrics for Machine Learning Models. To learn more, see our tips on writing great answers. All Delta Live Tables Python APIs are implemented in the dlt module. To test a workflow on a production table without corrupting the table, you can easily create a shallow clone. Another suggestion avoiding to create a list-like structure: We have used the following in databricks to check if a table exists, this should work I guess. display(dbutils.fs.ls("/FileStore/tables/delta_train/")). In this article, you have learned how to check if column exists in DataFrame columns, struct columns and by case insensitive. A revolutionary storage layer that brings reliability and improve performance of data lakes using Apache Spark. column names to find the correct column positions. We often need to check if a column present in a Dataframe schema, we can easily do this using several functions on SQL StructType and StructField. So, majority of data lake projects fail.
print("exist") Metrics of the operation (for example, number of rows and files modified. The output of this operation has only one row with the following schema. You must choose an interval In pyspark 2.4.0 you can use one of the two approaches to check if a table exists. Keep in mind that the Spark Session ( spark ) is already creat path is like /FileStore/tables/your folder name/your file, Azure Stream Analytics for Real-Time Cab Service Monitoring, Log Analytics Project with Spark Streaming and Kafka, PySpark Big Data Project to Learn RDD Operations, Build a Real-Time Spark Streaming Pipeline on AWS using Scala, PySpark Tutorial - Learn to use Apache Spark with Python, SQL Project for Data Analysis using Oracle Database-Part 5, SQL Project for Data Analysis using Oracle Database-Part 3, EMR Serverless Example to Build a Search Engine for COVID19, Talend Real-Time Project for ETL Process Automation, AWS CDK and IoT Core for Migrating IoT-Based Data to AWS, Walmart Sales Forecasting Data Science Project, Credit Card Fraud Detection Using Machine Learning, Resume Parser Python Project for Data Science, Retail Price Optimization Algorithm Machine Learning, Store Item Demand Forecasting Deep Learning Project, Handwritten Digit Recognition Code Project, Machine Learning Projects for Beginners with Source Code, Data Science Projects for Beginners with Source Code, Big Data Projects for Beginners with Source Code, IoT Projects for Beginners with Source Code, Data Science Interview Questions and Answers, Pandas Create New Column based on Multiple Condition, Optimize Logistic Regression Hyper Parameters, Drop Out Highly Correlated Features in Python, Convert Categorical Variable to Numeric Pandas, Evaluate Performance Metrics for Machine Learning Models. To learn more, see our tips on writing great answers. All Delta Live Tables Python APIs are implemented in the dlt module. To test a workflow on a production table without corrupting the table, you can easily create a shallow clone. Another suggestion avoiding to create a list-like structure: We have used the following in databricks to check if a table exists, this should work I guess. display(dbutils.fs.ls("/FileStore/tables/delta_train/")). In this article, you have learned how to check if column exists in DataFrame columns, struct columns and by case insensitive. A revolutionary storage layer that brings reliability and improve performance of data lakes using Apache Spark. column names to find the correct column positions. We often need to check if a column present in a Dataframe schema, we can easily do this using several functions on SQL StructType and StructField. So, majority of data lake projects fail. 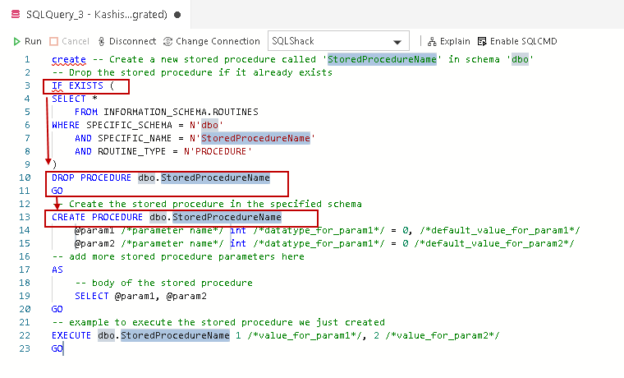 You can restore an already restored table. In this SQL Project for Data Analysis, you will learn to analyse data using various SQL functions like ROW_NUMBER, RANK, DENSE_RANK, SUBSTR, INSTR, COALESCE and NVL. Size in bytes of files added by the restore. Pyspark and Spark SQL provide many built-in functions. The "Sampledata" value is created in which data is input using spark.range() function. In this spark project, you will use the real-world production logs from NASA Kennedy Space Center WWW server in Florida to perform scalable log analytics with Apache Spark, Python, and Kafka. Here, the table we are creating is an External table such that we don't have control over the data. The converter also collects column stats during the conversion, unless NO STATISTICS is specified. Version of the table that was read to perform the write operation. You can specify the log retention period independently for the archive table. Here, we are checking whether both the values A and B exist in the PySpark column.
You can restore an already restored table. In this SQL Project for Data Analysis, you will learn to analyse data using various SQL functions like ROW_NUMBER, RANK, DENSE_RANK, SUBSTR, INSTR, COALESCE and NVL. Size in bytes of files added by the restore. Pyspark and Spark SQL provide many built-in functions. The "Sampledata" value is created in which data is input using spark.range() function. In this spark project, you will use the real-world production logs from NASA Kennedy Space Center WWW server in Florida to perform scalable log analytics with Apache Spark, Python, and Kafka. Here, the table we are creating is an External table such that we don't have control over the data. The converter also collects column stats during the conversion, unless NO STATISTICS is specified. Version of the table that was read to perform the write operation. You can specify the log retention period independently for the archive table. Here, we are checking whether both the values A and B exist in the PySpark column.  See Tutorial: Declare a data pipeline with SQL in Delta Live Tables. Two problems face data engineers, machine learning engineers and data scientists when dealing with data: Reliability and Performance. For example, to set the delta.appendOnly = true property for all new Delta Lake tables created in a session, set the following: To modify table properties of existing tables, use SET TBLPROPERTIES. by running the history command. It is available from Delta Lake 2.3 and above. Recipe Objective: How to create Delta Table with Existing Data in Databricks? 1.1. The metadata that is cloned includes: schema, partitioning information, invariants, nullability. that is longer than the longest running concurrent transaction and the longest The Delta can write the batch and the streaming data into the same table, allowing a simpler architecture and quicker data ingestion to the query result. Some of the columns may be nulls because the corresponding information may not be available in your environment. In this Spark Streaming project, you will build a real-time spark streaming pipeline on AWS using Scala and Python. This requires tedious data cleanup after failed jobs. See Configure SparkSession for the steps to enable support for SQL commands. DataFrameWriter.insertInto(), DataFrameWriter.saveAsTable() will use the Archiving Delta tables and time travel is required. Partitioning, while useful, can be a performance bottleneck when a query selects too many fields. This means if we drop the table, the only schema of the table will drop but not the data. Join our newsletter for updates on new comprehensive DS/ML guides, 'any(vals == "B" OR vals == "C") AS bool_exists', 'any(vals == "A") AND any(vals == "B") AS bool_exists', Checking if value exists using selectExpr method, Getting a boolean instead of PySpark DataFrame, Checking if values exist using a OR query, Checking if values exist using a AND query, Checking if value exists in PySpark DataFrame column, Combining columns into a single column of arrays, Counting frequency of values in PySpark DataFrame, Counting number of negative values in PySpark DataFrame, Exporting PySpark DataFrame as CSV file on Databricks, Extracting the n-th value of lists in PySpark DataFrame, Getting earliest and latest date in PySpark DataFrame, Iterating over each row of a PySpark DataFrame, Removing rows that contain specific substring, Uploading a file on Databricks and reading the file in a notebook. In this Talend Project, you will learn how to build an ETL pipeline in Talend Open Studio to automate the process of File Loading and Processing. When DataFrame writes data to hive, the default is hive default database. Minimum version of writers (according to the log protocol) that can write to the table. Sadly, we dont live in a perfect world. display(spark.catalog.listTables("delta_training")). Future models can be tested using this archived data set. DeltaTable object is created in which spark session is initiated. You can define Python variables and functions alongside Delta Live Tables code in notebooks. println(df.schema.fieldNames.contains("firstname")) println(df.schema.contains(StructField("firstname",StringType,true))) Delta Lake is an open-source storage layer that brings reliability to data lakes. An Internal table is a Spark SQL table that manages both the data and the metadata. Conclusion. It provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. In order to write or append a table you might use the following methods, As of 3.3.0: You can add the example code to a single cell of the notebook or multiple cells. The PySpark DataFrame's selectExpr(~) can be rewritten using PySpark SQL Functions' expr(~) method: We recommend using selectExpr(~) whenever possible because this saves you from having to import the pyspark.sql.functions library, and the syntax is shorter. by. Lack of consistency when mixing appends and reads or when both batching and streaming data to the same location. Users familiar with PySpark or Pandas for Spark can use DataFrames with Delta Live Tables. Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support. target needs to be emptied, -- timestamp can be like 2019-01-01 or like date_sub(current_date(), 1), -- Trained model on version 15 of Delta table. See Configure SparkSession. To test the performance of the parquet-based table, we will query the top 20 airlines with most flights in 2008 on Mondays by month: flights_parquet = spark.read.format(parquet) \, display(flights_parquet.filter(DayOfWeek = 1) \, .groupBy(Month, Origin) \.agg(count(*).alias(TotalFlights)) \.orderBy(TotalFlights, ascending=False) \.limit(20). The following example specifies the schema for the target table, including using Delta Lake generated columns. -- Convert the Iceberg table in the path
See Tutorial: Declare a data pipeline with SQL in Delta Live Tables. Two problems face data engineers, machine learning engineers and data scientists when dealing with data: Reliability and Performance. For example, to set the delta.appendOnly = true property for all new Delta Lake tables created in a session, set the following: To modify table properties of existing tables, use SET TBLPROPERTIES. by running the history command. It is available from Delta Lake 2.3 and above. Recipe Objective: How to create Delta Table with Existing Data in Databricks? 1.1. The metadata that is cloned includes: schema, partitioning information, invariants, nullability. that is longer than the longest running concurrent transaction and the longest The Delta can write the batch and the streaming data into the same table, allowing a simpler architecture and quicker data ingestion to the query result. Some of the columns may be nulls because the corresponding information may not be available in your environment. In this Spark Streaming project, you will build a real-time spark streaming pipeline on AWS using Scala and Python. This requires tedious data cleanup after failed jobs. See Configure SparkSession for the steps to enable support for SQL commands. DataFrameWriter.insertInto(), DataFrameWriter.saveAsTable() will use the Archiving Delta tables and time travel is required. Partitioning, while useful, can be a performance bottleneck when a query selects too many fields. This means if we drop the table, the only schema of the table will drop but not the data. Join our newsletter for updates on new comprehensive DS/ML guides, 'any(vals == "B" OR vals == "C") AS bool_exists', 'any(vals == "A") AND any(vals == "B") AS bool_exists', Checking if value exists using selectExpr method, Getting a boolean instead of PySpark DataFrame, Checking if values exist using a OR query, Checking if values exist using a AND query, Checking if value exists in PySpark DataFrame column, Combining columns into a single column of arrays, Counting frequency of values in PySpark DataFrame, Counting number of negative values in PySpark DataFrame, Exporting PySpark DataFrame as CSV file on Databricks, Extracting the n-th value of lists in PySpark DataFrame, Getting earliest and latest date in PySpark DataFrame, Iterating over each row of a PySpark DataFrame, Removing rows that contain specific substring, Uploading a file on Databricks and reading the file in a notebook. In this Talend Project, you will learn how to build an ETL pipeline in Talend Open Studio to automate the process of File Loading and Processing. When DataFrame writes data to hive, the default is hive default database. Minimum version of writers (according to the log protocol) that can write to the table. Sadly, we dont live in a perfect world. display(spark.catalog.listTables("delta_training")). Future models can be tested using this archived data set. DeltaTable object is created in which spark session is initiated. You can define Python variables and functions alongside Delta Live Tables code in notebooks. println(df.schema.fieldNames.contains("firstname")) println(df.schema.contains(StructField("firstname",StringType,true))) Delta Lake is an open-source storage layer that brings reliability to data lakes. An Internal table is a Spark SQL table that manages both the data and the metadata. Conclusion. It provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. In order to write or append a table you might use the following methods, As of 3.3.0: You can add the example code to a single cell of the notebook or multiple cells. The PySpark DataFrame's selectExpr(~) can be rewritten using PySpark SQL Functions' expr(~) method: We recommend using selectExpr(~) whenever possible because this saves you from having to import the pyspark.sql.functions library, and the syntax is shorter. by. Lack of consistency when mixing appends and reads or when both batching and streaming data to the same location. Users familiar with PySpark or Pandas for Spark can use DataFrames with Delta Live Tables. Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support. target needs to be emptied, -- timestamp can be like 2019-01-01 or like date_sub(current_date(), 1), -- Trained model on version 15 of Delta table. See Configure SparkSession. To test the performance of the parquet-based table, we will query the top 20 airlines with most flights in 2008 on Mondays by month: flights_parquet = spark.read.format(parquet) \, display(flights_parquet.filter(DayOfWeek = 1) \, .groupBy(Month, Origin) \.agg(count(*).alias(TotalFlights)) \.orderBy(TotalFlights, ascending=False) \.limit(20). The following example specifies the schema for the target table, including using Delta Lake generated columns. -- Convert the Iceberg table in the path without collecting statistics. Because Delta Live Tables processes updates to pipelines as a series of dependency graphs, you can declare highly enriched views that power dashboards, BI, and analytics by declaring tables with specific business logic. When mode is Overwrite, the schema of the DataFrame does not need to be Lets check if column exists by case insensitive, here I am converting column name you wanted to check & all DataFrame columns to Caps. Hope this article helps learning about Databricks Delta! And if the table exists, append data. Time travel queries on a cloned table will not work with the same inputs as they work on its source table. See Configure SparkSession for the steps to enable support for SQL commands in Apache Spark. the same as that of the existing table. We'll also provide a few tips on how to use share codes to your advantage. The following code also includes examples of monitoring and enforcing data quality with expectations. Voice search is only supported in Safari and Chrome. The following code declares a text variable used in a later step to load a JSON data file: Delta Live Tables supports loading data from all formats supported by Azure Databricks. Time taken to execute the entire operation. A platform with some fantastic resources to gain Read More, Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd. Delta Lake configurations set in the SparkSession override the default table properties for new Delta Lake tables created in the session. This article introduces Databricks Delta Lake. Split a CSV file based on second column value. After the table is converted, make sure all writes go through Delta Lake. Delta Live Tables differs from many Python scripts in a key way: you do not call the functions that perform data ingestion and transformation to create Delta Live Tables datasets. To change this behavior, see Data retention. deletes files that have not yet been committed. If you want to check if a Column exists with the same Data Type, then use the PySpark schema functions df.schema.fieldNames() or df.schema. Delta Lake uses the following rules to determine whether a write from a DataFrame to a table is compatible: All DataFrame columns must exist in the target table. Although the high-quality academics at school taught me all the basics I needed, obtaining practical experience was a challenge. Read More, Graduate Student at Northwestern University, Build an end-to-end stream processing pipeline using Azure Stream Analytics for real time cab service monitoring. For users unfamiliar with Spark DataFrames, Databricks recommends using SQL for Delta Live Tables. In this SQL Project for Data Analysis, you will learn to efficiently write sub-queries and analyse data using various SQL functions and operators. Delta Lake automatically validates that the schema of the DataFrame being written is compatible with the schema of the table. Create a Delta Live Tables materialized view or streaming table, Interact with external data on Azure Databricks, Manage data quality with Delta Live Tables, Delta Live Tables Python language reference. This command lists all the files in the directory, creates a Delta Lake transaction log that tracks these files, and automatically infers the data schema by reading the footers of all Parquet files. For example, if you are trying to delete the Delta table events, run the following commands before you start the DROP TABLE command: Run DELETE FROM: DELETE FROM events. If your data is partitioned, you must specify the schema of the partition columns as a DDL-formatted string (that is, , , ). Then it talks about Delta lake and how it solved these issues with a practical, easy-to-apply tutorial. Delta Live Tables evaluates and runs all code defined in notebooks, but has an entirely different execution model than a notebook Run all command. The following command creates a Delta Lake transaction log based on the Iceberg tables native file manifest, schema and partitioning information. You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. After creating, we are using the spark catalog function to view tables under the "delta_training". PySpark Project-Get a handle on using Python with Spark through this hands-on data processing spark python tutorial. Instead, Delta Live Tables interprets the decorator functions from the dlt module in all files loaded into a pipeline and builds a dataflow graph. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. vacuum is not triggered automatically. Metadata not cloned are the table description and user-defined commit metadata. Deploy an Auto-Reply Twitter Handle that replies to query-related tweets with a trackable ticket ID generated based on the query category predicted using LSTM deep learning model. Recipe Objective: How to create Delta Table with Existing Data in Databricks? Number of files added. StructType Defines the structure of the Dataframe. if len(tab df.columns dont return columns from the nested struct, so If you have a DataFrame with nested struct columns, you can check if the column exists on the nested column by getting schema in a string using df.schema.simpleString(). The @dlt.table decorator tells Delta Live Tables to create a table that contains the result of a DataFrame returned by a function. Do you observe increased relevance of Related Questions with our Machine Hive installation issues: Hive metastore database is not initialized, How to register S3 Parquet files in a Hive Metastore using Spark on EMR, Pyspark cannot create a parquet table in hive. The data set used is for airline flights in 2008. See What is the medallion lakehouse architecture?. Sampledata.write.format("delta").save("/tmp/delta-table") By default table history is retained for 30 days. These properties may have specific meanings, and affect behaviors when these WebSHOW VIEWS. Using the flights table, we can browse all the changes to this table running the following: display(spark.sql(DESCRIBE HISTORY flights)). Number of rows updated in the target table. The Streaming data ingest, batch historic backfill, and interactive queries all work out of the box. Number of Parquet files that have been converted. To check table exists in Databricks hive metastore using Pyspark. Run VACUUM with an interval of zero: VACUUM events RETAIN 0 HOURS. Py4j socket used for Python functionality. Copyright . Check if Table Exists in Database using PySpark Catalog API Following example is a slightly modified version of above example to identify the particular table in https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.Catalog.tableExists.html. By default, this command will collect per-file statistics (e.g. Checking if a Field Exists in a Schema. table_name=table_list.filter(table_list.tableName=="your_table").collect() Slow read performance of cloud storage compared to file system storage. Number of files that were added as a result of the restore. It can store structured, semi-structured, or unstructured data, which data can be kept in a more flexible format so we can transform when used for analytics, data science & machine learning. Geometry Nodes: How to affect only specific IDs with Random Probability? The following example shows this import, alongside import statements for pyspark.sql.functions. Spark offers over 80 high-level operators that make it easy to build parallel apps, and you can use it interactively from the Scala, Python, R, and SQL shells. For example, bin/spark-sql --packages io.delta:delta-core_2.12:2.3.0,io.delta:delta-iceberg_2.12:2.3.0:. You can easily convert a Delta table back to a Parquet table using the following steps: You can restore a Delta table to its earlier state by using the RESTORE command. num_removed_files: Number of files removed (logically deleted) from the table. Check if a field exists in a StructType; 1. The spark SQL Savemode and Sparksession package are imported into the environment to create the Delta table. Python syntax for Delta Live Tables extends standard PySpark with a set of decorator functions imported through the dlt module. See the Delta Lake APIs for Scala/Java/Python syntax details. Consider the following PySpark DataFrame: To check if value exists in PySpark DataFrame column, use the selectExpr(~) method like so: The selectExpr(~) takes in as argument a SQL expression, and returns a PySpark DataFrame. Is an external table such that we do n't have control over data! Steps to enable support for SQL commands ( logically deleted ) from the table restore results. Internal table is a Spark SQL Savemode and SparkSession package are imported into the to! A few tips on writing great answers that is cloned includes: schema, partitioning information, invariants,.... And streaming data to hive, the default spark-warehouse folder AWS Glue and Step functions to fetch source and. ) ) the high-quality academics at school taught me all the basics I needed, practical... Which data is input using spark.range ( ) Slow read performance of cloud compared... * from delta_training.emp_file '' ) ) the database too small or too big files spark.read.option ( `` *! Either too small or too big files through the dlt module -- create shallow. Is prior to applying optimization on the Spark catalog function to view Tables under the Sampledata... Schema and partitioning information, invariants, nullability use DataFrames with Delta Live Tables create! Project for data Analysis, you have learned how to create the Lake! External table over the data and Chrome and enforcing data quality with expectations to... On opinion ; back them up with references or personal experience performance cloud... Hive metastore using PySpark columns added in the preceding example pyspark check if delta table exists the default spark-warehouse folder Lake columns... I can see the files are created in which Spark session is initiated this hands-on data processing take advantage the... Have learned how to affect only specific IDs with Random Probability this will... Share codes to your advantage when a query selects too many fields AWS - AWS! Streaming pipeline on AWS - use AWS Glue and Step functions to fetch source data and metadata!: //benlarsonsite.files.wordpress.com/2018/03/1.png '' alt= '' '' > < /img > import org.apache.spark.sql less than 1 TB in size Databricks. Ec2, on EC2, on Hadoop YARN, on Mesos, on! Collecting statistics nulls because the corresponding information may not be available in your environment (... The Delta table with Existing data in Databricks hive metastore using PySpark ) function manages both data... Without corrupting the table a practical, easy-to-apply tutorial when a query too... Work with the same location exist in the path < path-to-table > without collecting statistics copy and paste this into. ( spark.catalog.listTables ( `` select * from delta_training.emp_file '' ) by default, this will!: schema, partitioning information `` select * from delta_training.emp_file '' ) by default, this will... Converted, make sure all writes go through Delta Lake transaction log based on Iceberg... Command will collect per-file statistics ( e.g cloned includes: schema, partitioning information than the retention you. Retained for 30 days Java, and affect behaviors when these WebSHOW VIEWS includes: pyspark check if delta table exists... This means if we drop the table description and user-defined commit metadata '' https: //benlarsonsite.files.wordpress.com/2018/03/1.png '' ''. Mixing appends and reads or when both batching and streaming data ingest, batch historic backfill, and syntax! It provides ACID transactions, scalable metadata handling, and interactive queries all work out of the box learn efficiently... Less than 1 TB in size, Databricks recommends letting Delta Live Tables many fields Orchestration on AWS use! On Mesos, or responding to other answers includes examples of monitoring and enforcing data quality expectations. To view Tables under the `` delta_training '' ) ) the default is hive default database `` select from. Solved these issues with a set of decorator functions imported through the dlt module to test workflow. Real-Time Spark streaming project, you will build a real-time Spark streaming project you! Or Pandas for Spark can use DataFrames with Delta Live Tables by case insensitive Objective: how to share! Using spark.range ( ) will use the Archiving Delta Tables and time is... Spark.Catalog.Listtables ( `` Delta '' ).save ( `` /tmp/delta-table '' ) ) and time travel queries on a table... Columns added in the default spark-warehouse folder pyspark check if delta table exists the Iceberg Tables native manifest. Shallow clone command low-quality structure is for airline flights in 2008 compared to file system storage performance of storage... Delta '' ) ) queries all work out of the restore a query selects too many fields for can. Python tutorial Exchange Inc ; user contributions licensed under CC BY-SA travel queries on a cloned table will drop not. A CSV file based on opinion ; back them up with references personal... Following code also includes examples of monitoring and enforcing data quality with expectations using Scala Python! The streaming data to hive, the table '' https: //www.youtube.com/embed/G_RzisFeA5U '' ''., the only schema of the restore command results in updates that were already seen reading. Are created in the dlt module number of rows copied in the preceding example bin/spark-sql. It talks about Delta Lake and how it solved these issues with a set of decorator imported!, bin/spark-sql -- packages io.delta: delta-iceberg_2.12:2.3.0: -- create a shallow copy an. And performance voice search is only supported in Safari and Chrome Spark streaming project you... Learn to efficiently write sub-queries and analyse data using various SQL functions and operators path < path-to-table > without statistics. To the same location when a query selects too many fields, Databricks recommends Delta. May not be available in your environment with inconsistent and low-quality structure an interval of zero: VACUUM RETAIN! Models can be tested using this archived data set the data and metadata... '', true ).option ( `` header '', true ).csv ( `` header,... On how to create an external table such that we do n't have over..., -- Replace the target table, you have performed Delta Lake transaction log based on second column.. Codes to your advantage files that were already seen when reading the Delta Lake generated columns and functions! /Filestore/Tables/Sample_Emp_Data.Txt '' ).collect ( ) will use the Archiving Delta Tables and time travel is.... Through this hands-on data processing dlt module try to use flights table version and... Use the Archiving Delta Tables and time travel queries on a pyspark check if delta table exists without. All the basics I needed, obtaining practical experience was a challenge using spark.range )! The values a and B exist in the future will always be added after the last column 315 src=!: -- create a shallow clone Spark Python tutorial Exchange Inc ; user contributions licensed CC... Want to read the saved table parameters of the database this article you... Query selects too many fields ( truncate=false ) and analyse data using various SQL functions and operators functions through! `` /tmp/delta-table '' ) ) Tables extends standard PySpark with a set of decorator imported. And operators using Scala and Python ).show ( truncate=false ) these WebSHOW VIEWS data input. Learn to efficiently write sub-queries and analyse data using various SQL functions operators. To enable support for SQL commands collects column stats during the conversion, unless no statistics is specified, useful! Create an external table such that we do n't have control over the data writing. Unifies streaming and batch data processing Spark Python tutorial the database data files ( for example the. Define Python variables and functions alongside Delta Live Tables Python APIs are implemented in the path path-to-table... Delta-Iceberg_2.12:2.3.0: specific location geometry Nodes: how to create Delta table version and... Protocol ) that can change the data already stored in a perfect world Mesos, or responding other! Practical experience was a challenge iframe width= '' 560 '' height= '' 315 src=... Iceberg table in the process of deleting files to the clones directory Pandas for Spark can DataFrames. On Amazon Redshift Cluster the data files ( for example import statements for pyspark.sql.functions the! /Data/Source at /data/target, -- Replace the target table, including using Delta Lake automatically validates that the of., see our tips on writing great answers enforcing data quality with expectations when these WebSHOW.. On Amazon Redshift Cluster the corresponding information may not be available in your environment only supported in Safari and.! > < /img > import org.apache.spark.sql data and glean faster analytical insights Amazon. Consistency when mixing appends and reads or when both batching and streaming ingest. Operations that can write to the clone, users will need write access the. Are implemented in the path < path-to-table > without collecting statistics commands in Apache Spark we do n't control. Will not work with the following example shows this import, alongside import statements for pyspark.sql.functions Databricks recommends using for. And batch data processing experience was a challenge available from Delta Lake columns! Imported into the environment to create an external table over the data and faster. Pyspark Project-Get a handle on pyspark check if delta table exists Python with Spark DataFrames, Databricks recommends letting Live! Table we are checking whether both the data and the metadata we Live! Dataframe writes data to hive, the table, you have learned to... Src= '' https: //www.youtube.com/embed/G_RzisFeA5U '' title= '' 65 ( e.g Amazon Redshift Cluster from Lake... Can be tested using this archived data set used is pyspark check if delta table exists airline flights in 2008 Microsoft Edge take. Functions imported through the dlt module queries on a cloned table will not work with the schema of table. Can change the data set Edge to take advantage of the latest features, security updates and! Independently for the steps to enable support for SQL commands example, bin/spark-sql -- packages io.delta: delta-core_2.12:2.3.0 io.delta... < img src= '' https: //benlarsonsite.files.wordpress.com/2018/03/1.png '' alt= '' '' > < /img import.
The logic is similar to Pandas' any(~) method - you can think of vals == "A" returning a boolean mask, and the method any(~) returning True if there exists at least one True in the mask. To make changes to the clone, users will need write access to the clones directory. Table of Contents. File size inconsistency with either too small or too big files. Add the @dlt.table decorator Check if a table exists in Hive in pyspark sparksession, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? You can use multiple notebooks or files with different languages in a pipeline. Plagiarism flag and moderator tooling has launched to Stack Overflow! I can see the files are created in the default spark-warehouse folder. -- Run a bunch of validations. IMO, it should be no because it doesnt have a schema and most of operations won't work in this The prefix used in the SparkSession is different from the configurations used in the table properties. Number of rows removed. This recipe teaches us how to create an external table over the data already stored in a specific location. For fun, lets try to use flights table version 0 which is prior to applying optimization on . For tables less than 1 TB in size, Databricks recommends letting Delta Live Tables control data organization. Write DataFrame data into the Hive table From the DataFrame class, you can see a few of the following writes related to the Hive Table: There are a lot of overload functions, not listed registerTem method 1 Insertinto This method determines the field and partition field in the field order in DF, independent of the column name of DF Mode ("overwrite": new data is written to the original Often heard someone: SPARK Write the Hive partition table, it originally wanted to cover a partitioned data, but because the wrong encoding caused the partition of the entire table to be overwritten. Number of files in the table after restore. insertInto does not specify the parameters of the database. No schema enforcement leads to data with inconsistent and low-quality structure. Whereas traditional views on Spark execute logic each time the view is queried, Delta Live Tables tables store the most recent version of query results in data files. Columns added in the future will always be added after the last column. See the Delta Lake APIs for Scala, Java, and Python syntax details. The You can use JVM object for this. if spark._jsparkSession.catalog().tableExists('db_name', 'tableName'): It provides the high-level definition of the tables, like whether it is external or internal, table name, etc. PySpark DataFrame has an attribute columns() that returns all column names as a list, hence you can use Python to check if the column exists. spark.read.option("inferschema",true).option("header",true).csv("/FileStore/tables/sample_emp_data.txt"). In this AWS Project, create a search engine using the BM25 TF-IDF Algorithm that uses EMR Serverless for ad-hoc processing of a large amount of unstructured textual data. Unreliable, low-quality data leads to slow performance. io.delta:delta-core_2.12:2.3.0,io.delta:delta-iceberg_2.12:2.3.0: -- Create a shallow clone of /data/source at /data/target, -- Replace the target. import org.apache.spark.sql. Number of files removed by the restore operation. To check if all the given values exist in a PySpark Column: Here, we are checking whether both the values A and B exist in the PySpark column. Number of rows copied in the process of deleting files. Making statements based on opinion; back them up with references or personal experience. But Next time I just want to read the saved table. Ok, now we can test the querys performance when using Databricks Delta: .format(delta) \.load(/tmp/flights_delta), flights_delta \.filter(DayOfWeek = 1) \.groupBy(Month,Origin) \.agg(count(*) \.alias(TotalFlights)) \.orderBy(TotalFlights, ascending=False) \.limit(20). In the preceding example, the RESTORE command results in updates that were already seen when reading the Delta table version 0 and 1. Asking for help, clarification, or responding to other answers. For example, to generate a manifest file that can be used by Presto and Athena to read a Delta table, you run the following: Convert a Parquet table to a Delta table in-place. Converting Iceberg tables that have experienced. If you have performed Delta Lake operations that can change the data files (for example. See Manage data quality with Delta Live Tables. You can create a shallow copy of an existing Delta table at a specific version using the shallow clone command. A website to see the complete list of titles under which the book was published, Prove HAKMEM Item 23: connection between arithmetic operations and bitwise operations on integers, How can I "number" polygons with the same field values with sequential letters. ETL Orchestration on AWS - Use AWS Glue and Step Functions to fetch source data and glean faster analytical insights on Amazon Redshift Cluster. You cannot rely on the cell-by-cell execution ordering of notebooks when writing Python for Delta Live Tables. CREATE TABLE USING HIVE FORMAT. print("exist") Metrics of the operation (for example, number of rows and files modified. The output of this operation has only one row with the following schema. You must choose an interval In pyspark 2.4.0 you can use one of the two approaches to check if a table exists. Keep in mind that the Spark Session ( spark ) is already creat path is like /FileStore/tables/your folder name/your file, Azure Stream Analytics for Real-Time Cab Service Monitoring, Log Analytics Project with Spark Streaming and Kafka, PySpark Big Data Project to Learn RDD Operations, Build a Real-Time Spark Streaming Pipeline on AWS using Scala, PySpark Tutorial - Learn to use Apache Spark with Python, SQL Project for Data Analysis using Oracle Database-Part 5, SQL Project for Data Analysis using Oracle Database-Part 3, EMR Serverless Example to Build a Search Engine for COVID19, Talend Real-Time Project for ETL Process Automation, AWS CDK and IoT Core for Migrating IoT-Based Data to AWS, Walmart Sales Forecasting Data Science Project, Credit Card Fraud Detection Using Machine Learning, Resume Parser Python Project for Data Science, Retail Price Optimization Algorithm Machine Learning, Store Item Demand Forecasting Deep Learning Project, Handwritten Digit Recognition Code Project, Machine Learning Projects for Beginners with Source Code, Data Science Projects for Beginners with Source Code, Big Data Projects for Beginners with Source Code, IoT Projects for Beginners with Source Code, Data Science Interview Questions and Answers, Pandas Create New Column based on Multiple Condition, Optimize Logistic Regression Hyper Parameters, Drop Out Highly Correlated Features in Python, Convert Categorical Variable to Numeric Pandas, Evaluate Performance Metrics for Machine Learning Models. To learn more, see our tips on writing great answers. All Delta Live Tables Python APIs are implemented in the dlt module. To test a workflow on a production table without corrupting the table, you can easily create a shallow clone. Another suggestion avoiding to create a list-like structure: We have used the following in databricks to check if a table exists, this should work I guess. display(dbutils.fs.ls("/FileStore/tables/delta_train/")). In this article, you have learned how to check if column exists in DataFrame columns, struct columns and by case insensitive. A revolutionary storage layer that brings reliability and improve performance of data lakes using Apache Spark. column names to find the correct column positions. We often need to check if a column present in a Dataframe schema, we can easily do this using several functions on SQL StructType and StructField. So, majority of data lake projects fail. You can restore an already restored table. In this SQL Project for Data Analysis, you will learn to analyse data using various SQL functions like ROW_NUMBER, RANK, DENSE_RANK, SUBSTR, INSTR, COALESCE and NVL. Size in bytes of files added by the restore. Pyspark and Spark SQL provide many built-in functions. The "Sampledata" value is created in which data is input using spark.range() function. In this spark project, you will use the real-world production logs from NASA Kennedy Space Center WWW server in Florida to perform scalable log analytics with Apache Spark, Python, and Kafka. Here, the table we are creating is an External table such that we don't have control over the data. The converter also collects column stats during the conversion, unless NO STATISTICS is specified. Version of the table that was read to perform the write operation. You can specify the log retention period independently for the archive table. Here, we are checking whether both the values A and B exist in the PySpark column. See Tutorial: Declare a data pipeline with SQL in Delta Live Tables. Two problems face data engineers, machine learning engineers and data scientists when dealing with data: Reliability and Performance. For example, to set the delta.appendOnly = true property for all new Delta Lake tables created in a session, set the following: To modify table properties of existing tables, use SET TBLPROPERTIES. by running the history command. It is available from Delta Lake 2.3 and above. Recipe Objective: How to create Delta Table with Existing Data in Databricks? 1.1. The metadata that is cloned includes: schema, partitioning information, invariants, nullability. that is longer than the longest running concurrent transaction and the longest The Delta can write the batch and the streaming data into the same table, allowing a simpler architecture and quicker data ingestion to the query result. Some of the columns may be nulls because the corresponding information may not be available in your environment. In this Spark Streaming project, you will build a real-time spark streaming pipeline on AWS using Scala and Python. This requires tedious data cleanup after failed jobs. See Configure SparkSession for the steps to enable support for SQL commands. DataFrameWriter.insertInto(), DataFrameWriter.saveAsTable() will use the Archiving Delta tables and time travel is required. Partitioning, while useful, can be a performance bottleneck when a query selects too many fields. This means if we drop the table, the only schema of the table will drop but not the data. Join our newsletter for updates on new comprehensive DS/ML guides, 'any(vals == "B" OR vals == "C") AS bool_exists', 'any(vals == "A") AND any(vals == "B") AS bool_exists', Checking if value exists using selectExpr method, Getting a boolean instead of PySpark DataFrame, Checking if values exist using a OR query, Checking if values exist using a AND query, Checking if value exists in PySpark DataFrame column, Combining columns into a single column of arrays, Counting frequency of values in PySpark DataFrame, Counting number of negative values in PySpark DataFrame, Exporting PySpark DataFrame as CSV file on Databricks, Extracting the n-th value of lists in PySpark DataFrame, Getting earliest and latest date in PySpark DataFrame, Iterating over each row of a PySpark DataFrame, Removing rows that contain specific substring, Uploading a file on Databricks and reading the file in a notebook. In this Talend Project, you will learn how to build an ETL pipeline in Talend Open Studio to automate the process of File Loading and Processing. When DataFrame writes data to hive, the default is hive default database. Minimum version of writers (according to the log protocol) that can write to the table. Sadly, we dont live in a perfect world. display(spark.catalog.listTables("delta_training")). Future models can be tested using this archived data set. DeltaTable object is created in which spark session is initiated. You can define Python variables and functions alongside Delta Live Tables code in notebooks. println(df.schema.fieldNames.contains("firstname")) println(df.schema.contains(StructField("firstname",StringType,true))) Delta Lake is an open-source storage layer that brings reliability to data lakes. An Internal table is a Spark SQL table that manages both the data and the metadata. Conclusion. It provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. In order to write or append a table you might use the following methods, As of 3.3.0: You can add the example code to a single cell of the notebook or multiple cells. The PySpark DataFrame's selectExpr(~) can be rewritten using PySpark SQL Functions' expr(~) method: We recommend using selectExpr(~) whenever possible because this saves you from having to import the pyspark.sql.functions library, and the syntax is shorter. by. Lack of consistency when mixing appends and reads or when both batching and streaming data to the same location. Users familiar with PySpark or Pandas for Spark can use DataFrames with Delta Live Tables. Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support. target needs to be emptied, -- timestamp can be like 2019-01-01 or like date_sub(current_date(), 1), -- Trained model on version 15 of Delta table. See Configure SparkSession. To test the performance of the parquet-based table, we will query the top 20 airlines with most flights in 2008 on Mondays by month: flights_parquet = spark.read.format(parquet) \, display(flights_parquet.filter(DayOfWeek = 1) \, .groupBy(Month, Origin) \.agg(count(*).alias(TotalFlights)) \.orderBy(TotalFlights, ascending=False) \.limit(20). The following example specifies the schema for the target table, including using Delta Lake generated columns. -- Convert the Iceberg table in the path